{kind=link}
I started looking into the foundations of ChatGPT and Friends a year ago and I’ve been writing and speaking about ChatGPT and Friends for about half a year now, resulting in this collection of explanations and illustrations of what LLMs and other Generative AIs do, and especially attempting to counter the hype and fever with some cool realities. It sometimes feels like trying to convince people that buying tulip bulb options really is less of a certain investment than they think.
One of the use cases I thought was reasonable to expect (until now) was summarising. It turns out I was wrong. Because ChatGPT isn’t summarising at all, it only looks like it. What it does is something else and that something else only becomes summarising in very specific circumstances. In hindsight I should have expected this.
Here is what happened. Last week, I was asked to create a summary of a 50-page public paper by Netspar, the Network for Studies on Pensions, Aging and Retirement. The (public) paper is called De governance van pensioenfondsen vanaf de stelselwijziging (The governance of pension funds following the system change). Actually, creating the summary was discussed at a meeting with other people present and at that meeting I had promised to try to create the summary somewhere in the week that followed. The next day, a friendly colleague sent me his own summary (or so it seemed), to which my reaction (without reading it) was: “OK, he has already done it, the show-off. I probably don’t need to do it anymore”. But that was a mistake as I had not read the entire mail which stated “I had ChatGPT make a summary, because ‘why not?’. Maybe it is useful for you”. I decided not to read ChatGPT’s summary, but create my own and then compare the two.
So, I studied the paper, and created my summary.
In short, the paper looks at the context and consequences of the systemic change that is currently going on in the Dutch pension system (we’re currently doing a complex €1.6 trillion transformation in about 6 years, 2 of which have already passed, everything is still preparatory up to now), and it concludes for instance that:
- the changes will require a different focus of the pension funds (less keeping an eye on fairness as this is no longer something the pension fund has a lot of freedom on, but more keeping a eye on operational excellence with respect to the mechanisms agreed upon)
- the new situation should come with a stronger governance role by the parties participating in the pension schemes (people saving, people receiving pensions, employers) in the form of an elected College van Belanghebbenden (Council of Stakeholders), mainly because the systemic change moves all of the risks to the (collective of) people participating in a pension fund, whose legal positions are weak.
ChatGPT’s summary contained mostly things that can be found in the full text. There was the occasional incorrectness of course. The paper itself, for instance, argues that ‘regulatory strategies’ (rules and compliance) do not really work all that well (e.g. costly, not agile), and that thus an organisational governance structure should be strengthened. I.e. there should be organisational elements with powers to affect one another, such as that council of stakeholders they propose with the power to sack board members. But ChatGPT’s summary of the ‘Summary’ chapter says that such regulations will strengthen governance. (And yep, the paper actually comes with its own summary chapter, so the easiest — but not the best — summary would have been a simple copy-paste operation…)
But the main proposal — that Council of Stakeholders — which takes up about 25% of the main text of the paper, is not mentioned in ChatGPT’s summary at all. Instead, that concrete suggestion becomes a few empty sentences. And that was true for a few other essential elements of the paper. In other words: the summary makes a good first impression, though not very concrete in terms of proposals, but reading the summary alone, you will not be aware that the paper actually has a a set of very concrete proposals and options, most of which is missing in ChatGPT’s summary.
I wondered why, and — after studying the summary — I think I know: ChatGPT doesn’t summarise if you ask it to.
No really: ChatGPT doesn’t summarise. When I asked ChatGPT to summarise this text, it instead shortened the text. And there is a fundamental difference between the two. To summarise, you need to understand what the paper is saying. To shorten text, not so much. To truly summarise, you need to be able to detect that from 40 sentences, 35 are leading up to the 36th, 4 follow it with some additional remarks, but it is that 36th that is essential for the summary and that without that 36th, the content is lost.
[Addendum 2024/09/16: this article has been making the rounds a bit, and the observation above is then generally quoted. I changed it just now to a first person, because the full conclusion is below and is slightly more diverse. While I’m at it, the following two posts are relevant in this context. First the one that discusses the insight by Brian Merchant that GenAI doesn’t need to be good to be disruptive. GenAI introduces the category ‘cheap’ in several activities. The other dives a bit deeper into the role of parameters to steer the content in the most extreme form: Memorisation, e.g. fully reproducing Shakespeare’s Sonnet 18 from patterns stored in the parameters]
But that requires a real understanding that is well beyond large prompts (the entire 50-page paper) and hundreds of billions of parameters.
Addendum 2024/05/09: I just realised the situation is even worse. If I have 35 sentences of circumstance leading up to a single sentence of conclusion, the LLM mechanism will — simply because of how the attention mechanism works with the volume of those 35 — find the ’35’ less relevant sentences more important than the single key one. So, in a case like that it will actively suppress the key sentence.
So, when will shortening the text be good enough for a reliable summary? Probably only when summarising consists of nothing else than turning something unnecessarily repetitive and long-winding into something short, i.e. when volume is a good predictor of importance. That is far less of a use case than people think. In the meantime, the result itself will — errors and all — suggest to readers that it is a true and reliable summary and we’re not going to doubt that, human as we are. It really might take a while until people have experienced enough of this for GPT-fever to pass. After this experience with summarising — something that was on my list as a potential realistic use case — I am less optimistic that there will be reliable enough use cases for LLMs for real business uses.
[Addendum 28 May]
I tried to find a real English language example to show the effect.
I first tried to let ChatGPT one of my key posts (the one about the role convictions play in humans with an addendum about human ‘wetware’). ChatGPT made a total mess of it. What it said had little to do with the original post, and where it did, it said the opposite of what the post said. What seemed to happen is that ChatGPT’s parameters — which have been tuned by its training data — dominate the result. The text to be summarised itself hardly influences the summary.
For fun, I asked Gemini as well. Gemini didn’t make a mistake and actually produced something that is a very short summary of the post,
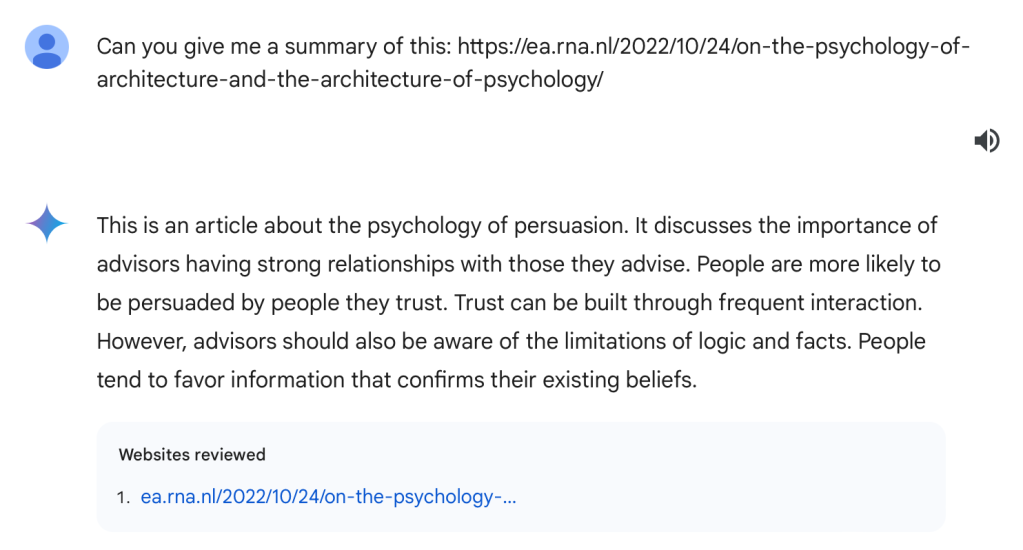
but it is extremely short so it leaves most out. So, I asked Gemini to expand a little,
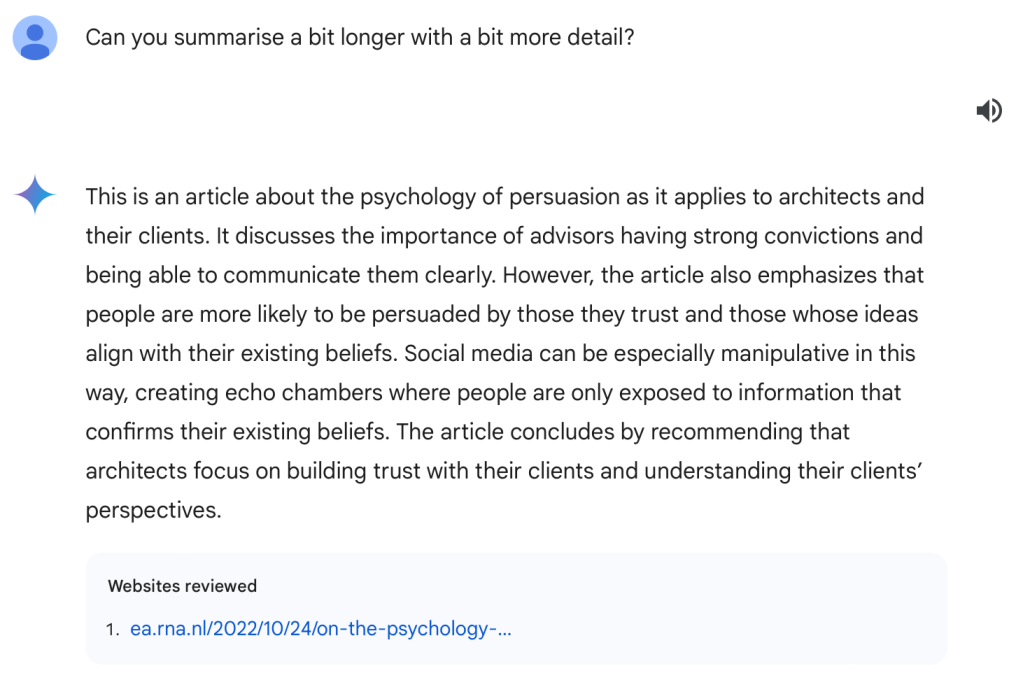
but as soon as I did that, it fabricated something that is not in the original article (quite the opposite), i.e.: “It discusses the importance of advisors having strong convictions and being able to communicate them clearly.” Nope. Not there.
This attempt did not clearly show the ‘shortening’ effect I had noticed before. Asking for a longer summary did show the parameters starting do dominate over the prompt (the ‘context’, technically), e.g. by producing “The article concludes by recommending that architects focus on building trust with their clients and understanding their clients’ perspectives.”, which is also nowhere in the article summarised.
So, what we see here is something that one sees more often. The mechanism of an LLM has two parts influencing the calculation of the generated text: (1) the context (the prompts and answers up until the last generated or user-typed text), and (2) the parameters (based on all the training material). And we’ve seen before that these may ‘pull’ in different directions. E.g. the Crescendo jailbreak (circumventing the safety of LLMs) is based on overcoming the power of the parameters by using the context.
To find another ‘shortening is not summarising’ example, I tried letting it summarise Plato’s Protagoras (a favourite), but that was a stupid plan. Plato’s work and commentaries about it are all over the internet and books, so the parameters of the LLM absolutely dominate the result. And given the amount of training material, the result from the parameters is nearing memorisation quality, so pretty good.
In the end, another Netspar paper, but an English one: Regulating pensions: Why the European Union matters from 2011 gave me a working example. I had ChatGPT create a 500-word summary from that paper and it produced:
The key points and proposals in the original paper (mostly in sections 5 and 6, the summary — yes, there is again already a summary in the paper, which ChatGPT completely ignores) on page 45) are:
- The IORP directive is unclear and leads to a distortion of the market
- ChatGPT instead — clearly from parameters/training: The IORP Directive establishes a framework for occupational retirement provision across the EU. It ensures that pension funds are well-regulated, secure, and capable of providing adequate benefits to retirees. The directive’s scope and implementation in various member states are critical for a cohesive EU pension system.
- Separate pensions in economic and non-economic activities and regulate only the economic ones at EU level
- This is missing from the ChatGPT summary
The summary by ChatGPT is pretty often empty waffle. It almost feels like a psychic con (I think I read this analogy somewhere — [update 29/07/2024: found it again, it is this post from Baldur Bjarnason]) with its always-true generalisations that do not make an actual point, e.g.:
- ChatGPT: The constitutional dimension of SGEI within the Treaty framework sets the stage for how pensions are regulated and the legal obligations of member states
- ChatGPT: The paper concludes that understanding and integrating EU regulations is essential for national pension policymakers. The interplay between national policies and EU law is complex but necessary for the sustainability and adequacy of pension systems across Europe.
This is not nonsense. But at the same time, as part of the summary it does not make sense. We cannot do anything with it (and thus, following Uncle Ludwig, it is meaningless)
Conclusion about ‘summarising’ by LLM Chatbots
‘Summarising’ by LLM Chatbots seems to be influenced by two key inputs of text generation calculations:
- The parameters — which come from the training material.
- If the subject is well-represented by the parameters (there has been lots of it in the training material), the parameters dominate the summary more and the actual text you want to summarise influences the summary less. Hence: LLM Chatbots are pretty bad in making specific summaries of a subject that is widespread;
- The context — which is the prompts and answers up to this point in the chat, including the text you have given to summarise.
- If the context is relatively small, it has little influence and the result is dominated by the parameters, so not by the text you are trying to summarise;
- If the context is large enough and the subject is not well-represented by the parameters (there hasn’t been much about it in the training material), the text you want to summarise dominates the result. But the mechanism you will see is ‘text shortening‘, not true summarising.
Having said that, that very short initial summary of Gemini of my post was pretty good (though incomplete). But it for instance left out the entire part in the article about human brains. So I asked it specifically as a follow-up question, and it told me:

‘Likely’? ‘Might’? Never mind. But this summary is absolutely not a summary of that part of the story. Pure fabrication coming from the parameter side of the LLM calculations (which it even ‘admits’ in the final paragraph saying it is making an ‘educated [sic] guess’). ‘Educated guess’, that is bamboozling us right there. But more importantly, why guessing on the basis of the parameters instead of providing the summary as asked? If you want to see intelligence here, you really have to want to. Desperately.
So:
Actual text ‘summarising’ — when it happens (instead of mostly generation-from-parameters) — by LLMs looks more like ‘text shortening’ and that is not the same
By the way: I find asking ChatGPT for a summary of a paper that already has a summary included, and ChatGPT ignoring that summary, actually a pretty effective illustration that there is fundamentally no understanding in LLMs, not even ’emerging’.
PS. Gemini says (see above) in a footnote: “Websites reviewed: [ea.rna.nl/2022/10/24/on-the-psychology-…]”. I have not been able to ascertain that this is true, because Gemini also denies it used the website to make a summary (which is weird given the correct summary). So, did it add the content of the web site to the prompt, or was the web site part of the training? Inquiring minds would like to know.
PPS. I have been sitting on a post that suggests we should look at LLM outputs as being influenced by three recognisable elements: the parameter volume, the training data, and the context. Each have distinguishable effects, but that is for next time. Maybe.
Appendix 2024/09/15
Because I want to offer full transparency, the edit I did (because people quoted only one part of the conclusion) made me revisit Gemini. And I found out what happened above. Gemini was unable to read the web page live for summarising. Apparently, Google has built a ‘summary database’ for a large part of the web and it accesses that cache and not the real web page when it created the initial summary. So, I was actually bamboozled into thinking it did the summarising live by Gemini’s first answer. It is hardly the case that it could read the first part and not the second, after all.
So, I copy-pasted the part of the article I wanted it to summarise into the prompt. And it came up with three summarising drafts of which this one was the shortest (and actually best, though it presented the longest one as the prime answer).
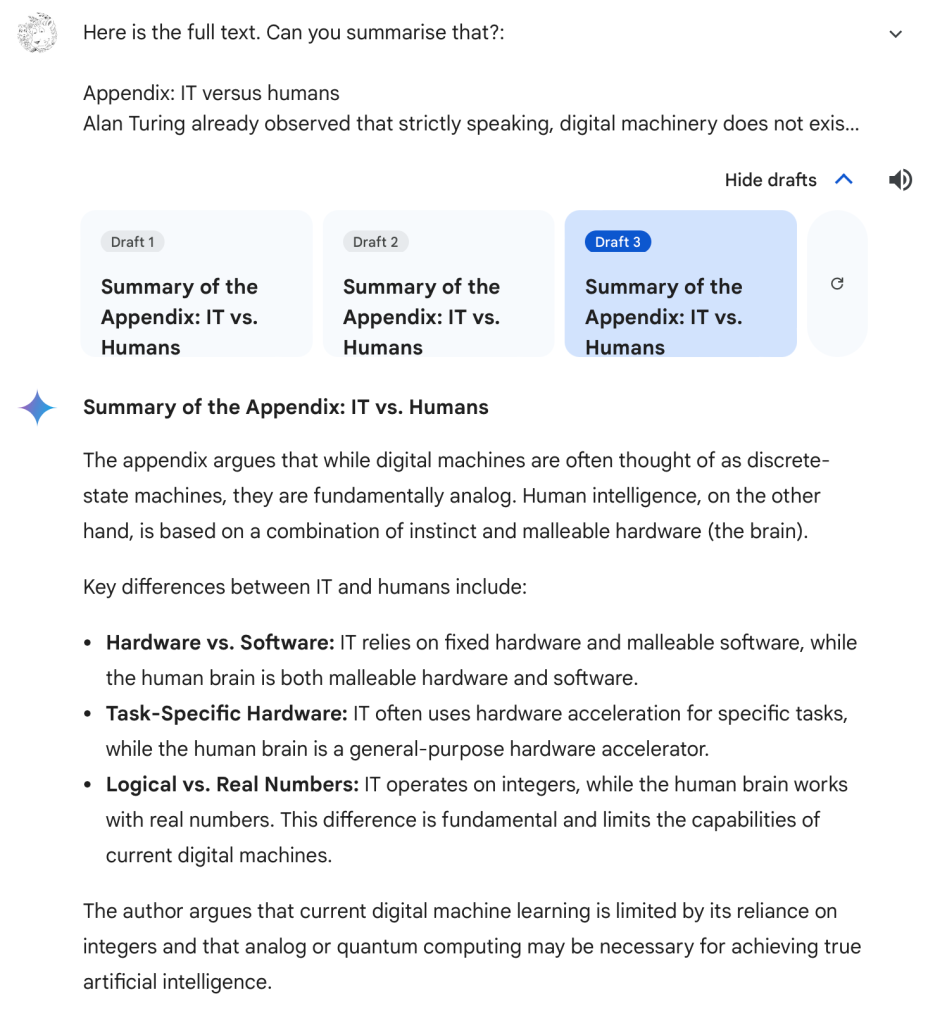
This one is actually pretty good (the other drafts are longer and include irrelevant detail, the longest one with most irrelevant detail was selected as the prime answer). The article says the brain can be seen as mostly ‘malleable instinct implemented as malleable hardware’, so “instinct and malleable hardware” is wrong and if you read the article you’ll see that “malleable hardware and software” gives off a wrong impression, though it is logically correct (yep, that is possible in human language…).
So, it seems what happened with the original Gemini summary was this. The input was the ‘summary database’ of Google and the LLM produced a ‘fabrication’ from that, it ignored the actual article. Indeed ‘it did nothing of the kind’.
GenAI introduces the category ‘cheap’ in several activities is so spot on…
This article is part of the ChatGPT and Friends Collection. In case you found any term or phrase here unclear or confusing (e.g, I can understand that most people do not immediately know that ‘context’ in LLMs is whatever has gone before in human (prompt) and LLM (reply) generated text, before producing the next token), you can probably find a clear explanation there.
[You do not have my permission to use any content on this site for training a Generative AI (or any comparable use), unless you can guarantee your system never misrepresents my content and provides a proper reference (URL) to the original in its output. If you want to use it in any other way, you need my explicit permission]