
{kind=link}
Data is the fuel for AI; modern data is even more important for generative AI and advanced data analytics, producing more accurate, relevant, and impactful results. Modern data comes in various forms: real-time, unstructured, or user-generated. Each form requires a different solution. AWS’s data journey began with Amazon Simple Storage Service (Amazon S3) in 2006, marking the start of cloud-based data storage at scale. Since then, AWS has expanded its data offerings to cover the entire data lifecycle, offering a comprehensive ecosystem of services designed to harness the full potential of modern data, from ingestion and storage to processing and analysis, supporting the entire lifecycle of AI-driven innovation.
In this blog post, we will cover some AWS use cases for modern data architectures, showing how AWS enables organizations to leverage the power of data and generative AI technologies.
This blog focuses on selecting the right database for generative AI applications and provide knowledge that can enhance your understanding, guide your decision making, and ultimately lead to more successful AI projects. Selecting the right database for generative AI applications is not just about storage; it significantly impacts performance, scalability, ease of integration, and overall effectiveness of the AI solution.
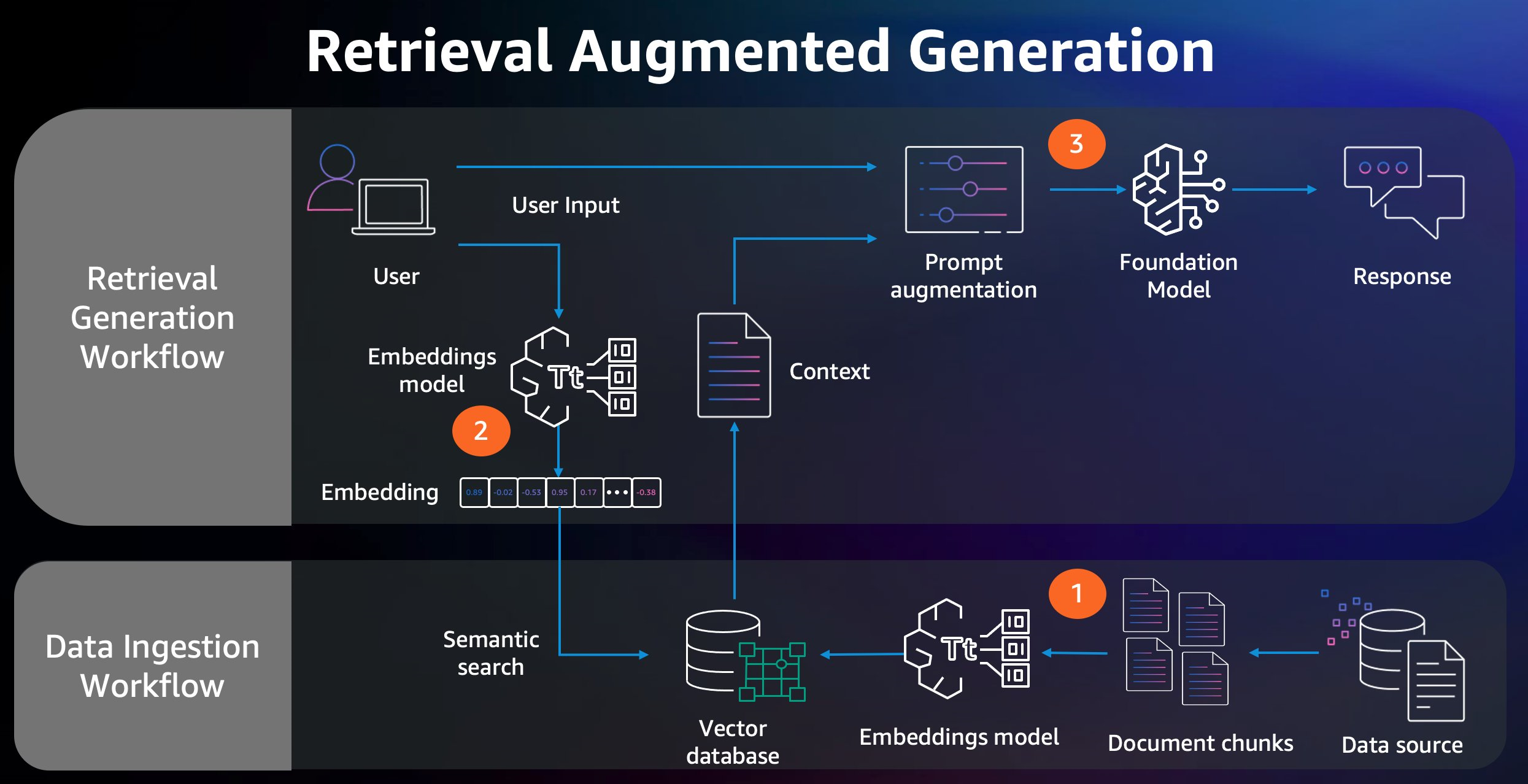
Figure 1. Diagram that shows the key steps in a RAG workflow
Take me to this blog
Adopting a data mesh architecture can enhance an organization’s ability to manage data effectively, leading to improved performance, innovation, and overall business success. In this guidance, you will discover some strategies to build data mesh solutions on AWS.
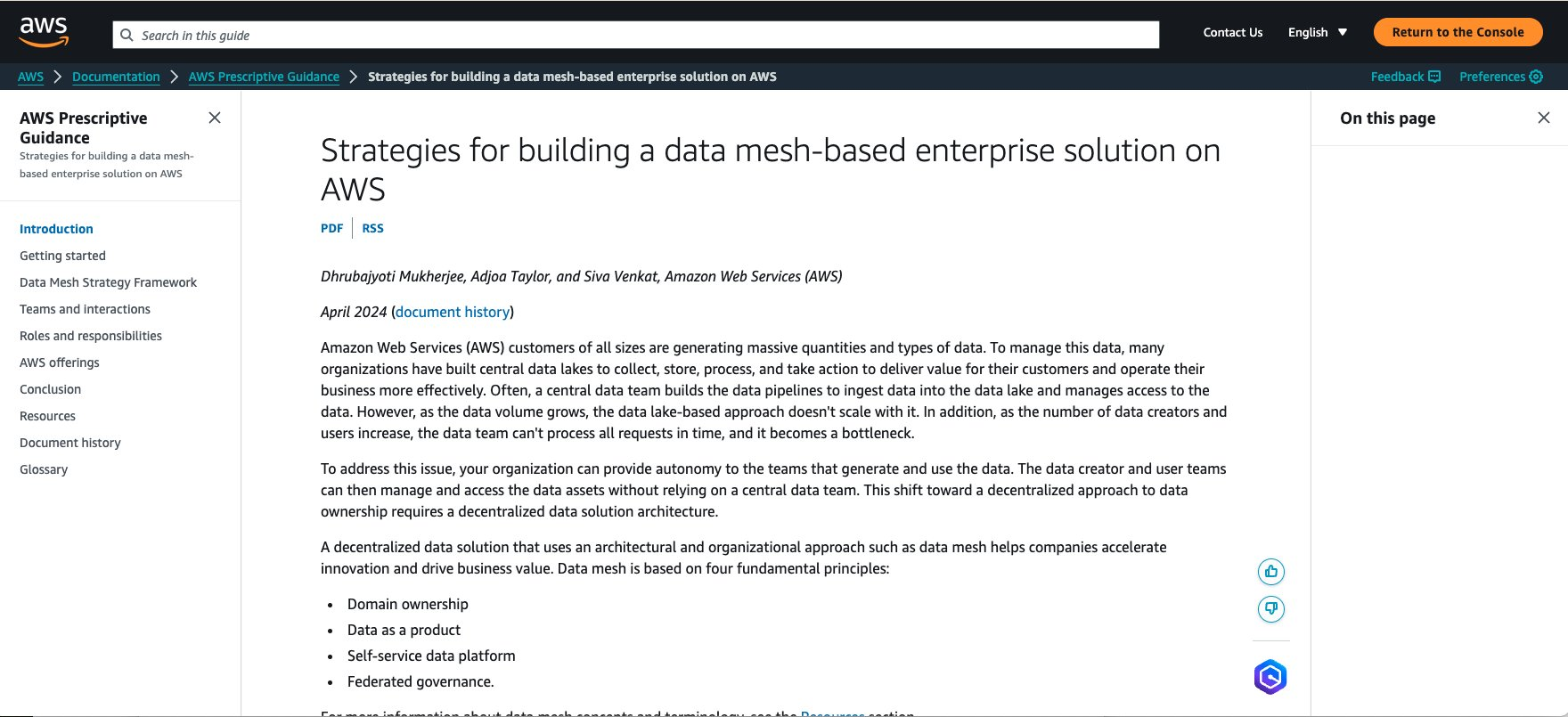
Figure 2. The data mesh organizes data into domains, where data are seen as quality products to expose for consumption
Take me to this guidance
Amazon S3 is an object storage service that supports multiple use cases, including data architectures. Big data pipelines can use Amazon S3 to store input, output, and intermediate results. Machine learning systems use Amazon S3 to process application logs and build the datasets both for experimentation and for production model training. Given the importance of the service and the number of use cases that a foundational storage service can support, we want to share best practices, performance optimization, and cost optimization strategies to work with Amazon S3. This video shows how Anthropic designs its architecture around Amazon S3 in their data architecture.

Figure 3. Workloads with predictable patterns often have low retrieval rates for long periods of time after, so we can design to adopt cheaper storage classes for them
Take me to this video
If you are curious about the underlying architecture of Amazon S3 and want to drill down into its internal design, you can watch the re:Invent video Dive deep on Amazon S3.
This is an AWS case study on how HPE Aruba Supply Chain successfully re-architected and deployed their data solution by adopting a modern data architecture on AWS. The new solution has helped Aruba integrate data from multiple sources, along with optimizing their cost, performance, and scalability. This has also allowed the Aruba Supply Chain leadership to receive in-depth and timely insights for better decision-making, thereby elevating the customer experience.
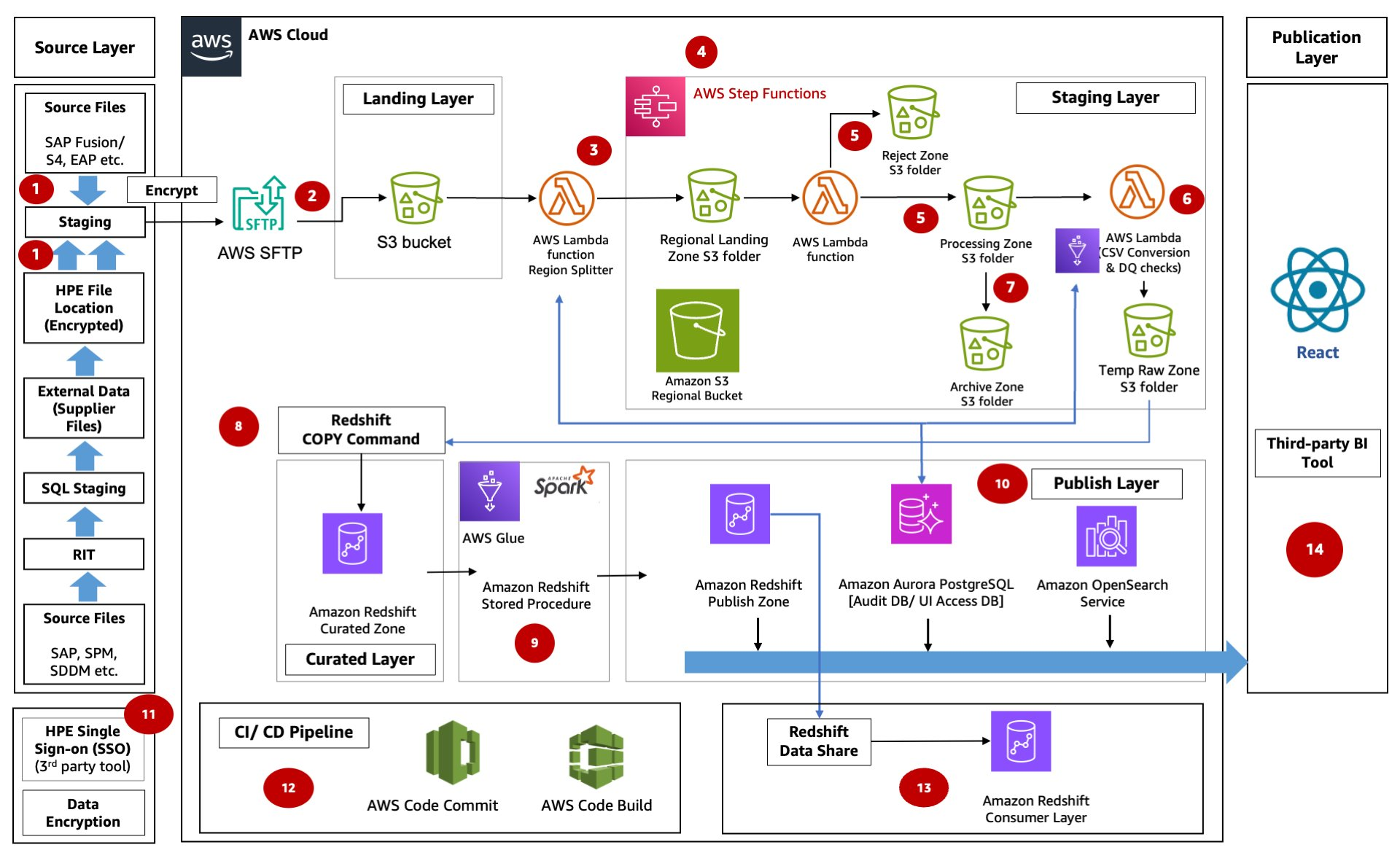
Figure 4. Reference architecture diagram showing HPE Aruba Supply Chain’s architecture, featuring Amazon S3
Take me to this blog
AWS Modern Data Architecture Immersion Day
This workshop highlights advantage of adopting a modern data architecture on AWS. By integrating the flexibility of a data lake with specialized analytics services, organizations can significantly enhance their data-driven decision-making capabilities. We encourage everyone to explore how this architecture can streamline their analytics processes and support diverse use cases, from real-time insights to advanced machine learning. It’s an excellent opportunity to leverage modern data architecture.
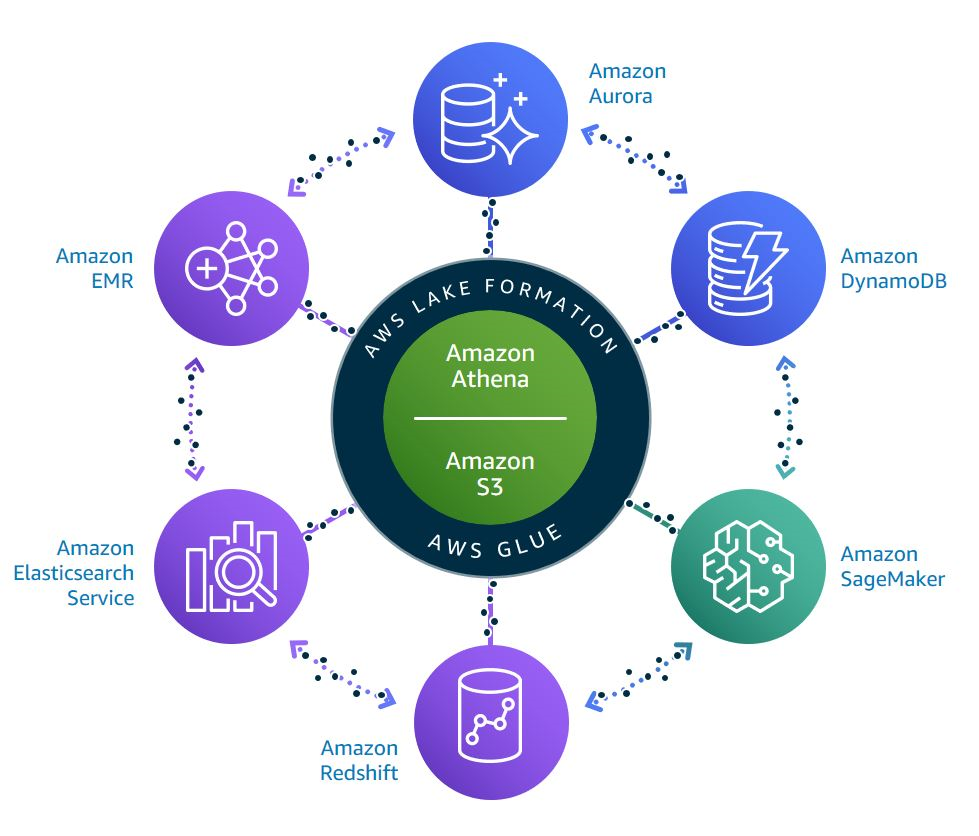
Figure 5. Data architectures are fundamental to power use cases ranging from analytics to machine learning
Take me to this workshop
See you next time!
Thanks for reading! In the next blog, we will cover some tips on how to get the best out of your developer experience on AWS. To revisit any of our previous posts or explore the entire series, visit the Let’s Architect! page.