{kind=link}
Post Views: 595
An illustrative blog with a reference application applying Snowflake Cortex
With Generative AI in mainstream adoption, Snowflake has shared its Generative AI Vision in the past to bring Gen AI and LLMs closer to the customers’ data. Snowflake’s Cortex AI is their fully managed service (GA on May 24) to manage LLMs and the entire lifecycle for diverse business and technical users:
This article shares the key architecture and design approaches and related components for building Generative AI applications using Snowflake Cortex AI for enterprises, using an illustrative Search and Chat AI Assistant as a reference application.
- Application Development using Streamlit: Since its acquisition in 2022, Streamlit (an Opensource platform for building Python-based apps), has been integrated into Snowflake’s ecosystem to build data-driven apps.
- Processing with Document AI (Managed AI Service) as part of Cortex AI: The following cloud-based AI services are available for processing documents to turn unstructured data into structured data.
- Search capability with Universal Search (Managed AI Service) as part of Cortex AI: LLM-based search capability built on search engine technology acquired from Neeva.
- Gen AI Assistant with Snowflake Copilot: Providing natural language interface to generated SQL queries applying Text2SQL LLM techniques.
- LLM Functions to leverage Gen AI-powered functions for easy development: COMPLETE, EMBED_TEXT_768, SENTIMENT, EXTRACT_ANSWER, SUMMARIZE, and TRANSLATE.
- ML Functions to automate predictions and insights into your data using machine learning capabilities such as Forecasting, Anomaly Detection, Classification, and more.
- Managed Abstraction Layer to interface with Multiple LLMs: Cortex offers access to a wide range of industry-leading LLMs including Snowflake’s own LLM — Snowflake Arctic.
Considering the above rich AI capabilities being offered by Snowflake, let’s build the application architecture applying the RAG pattern for enterprise search and chat application as shown below (
Protip: Continuous and evolutionary architecture practices help to build solution architecture incrementally than trying to build the perfect architecture during the initial stages.
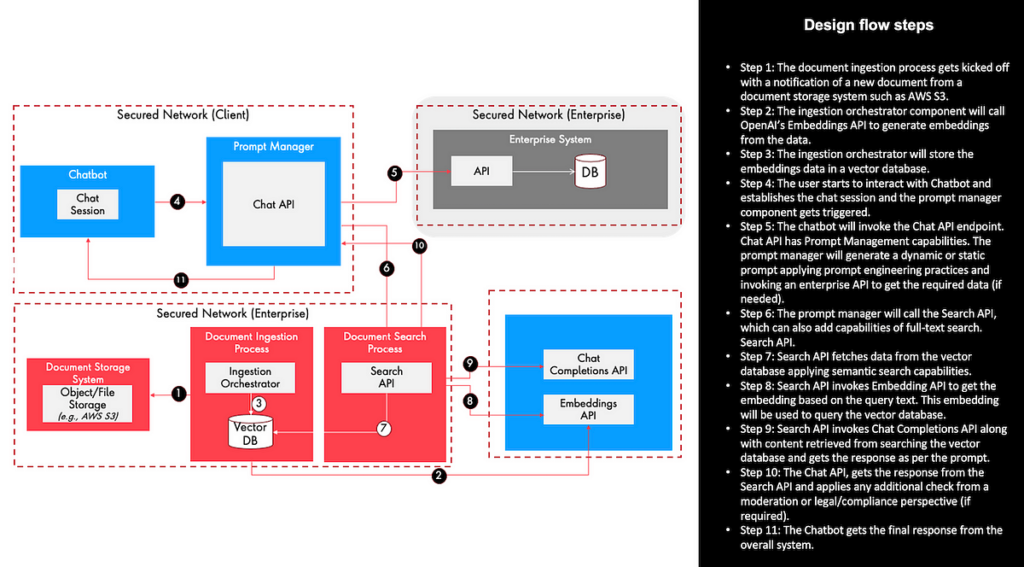
Key business features:
- single, unified conversational interface to query internal documents, research reports, and client data using natural language
- derive meaningful insights from the knowledge base for advisors to accelerate and increase the efficiency of their workflows
- provide a natural language interface to query data
- user-intent classification to figure out what the user is seeking
- render chart from the curated and analyzed data
- derive meaningful answers and insights from the unstructured and structured data
Considering Snowflake Cortex AI provides the optionality to choose different LLMs and frameworks, here is the technology stack selected to build the application using Snowflake Cortex AI and Snowflake Services:
- Chat Experience: using Streamlit to build a quick prototype and integrated experience with Snowsight helps to build data apps faster. Please ensure that the Python libraries you need are already available in hosted Streamlit by Snowflake.
- Unstructured Data Ingestion & Processing: using Snowpark to ingest unstructured files (e.g. PDFs, etc.) in Java, Python, or Scala using a user-defined function (UDF), user-defined table function (UDTF), or stored procedures. Alternatively, you can use document processing capability such as Document AI to create a data processing pipeline or you can use Snowsight’s Stage feature for loading data directly into Snowflake tables. Reference data can be stored in AWS S3 or GCP Storage or Azure storage container. PDF chunking and related processing can be done using the framework like LangChain such as below:
create or replace function pdf_text_chunker(file_url string)
returns table (chunk varchar)
language python
runtime_version = '3.9'
handler="pdf_text_chunker"
packages = ('snowflake-snowpark-python','PyPDF2', 'langchain')
as
$$
from snowflake.snowpark.types import StringType, StructField, StructType
from langchain.text_splitter import RecursiveCharacterTextSplitter
from snowflake.snowpark.files import SnowflakeFile
import PyPDF2, io
import logging
import pandas as pd
class pdf_text_chunker:
def read_pdf(self, file_url: str) -> str:
logger = logging.getLogger("udf_logger")
logger.info(f"Opening file {file_url}")
with SnowflakeFile.open(file_url, 'rb') as f:
buffer = io.BytesIO(f.readall())
reader = PyPDF2.PdfReader(buffer)
text = ""
for page in reader.pages:
try:
text += page.extract_text().replace('\n', ' ').replace('\0', ' ')
except:
text = "Unable to Extract"
logger.warn(f"Unable to extract from file {file_url}, page {page}")
return text
def process(self,file_url: str):
text = self.read_pdf(file_url)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 4000,
chunk_overlap = 400,
length_function = len
)
chunks = text_splitter.split_text(text)
df = pd.DataFrame(chunks, columns=['chunks'])
yield from df.itertuples(index=False, name=None)
$$;Semantic Search with Vector Database: Snowflake provides the integrated capability to use Cortex LLM functions to generate embeddings and store it in the Snowflake table. You don’t need a separate vector database to store embedding — a sample code below:
insert into docs_vector_table (relative_path, size, file_url,
scoped_file_url, chunk, chunk_vec)
select relative_path,
size,
file_url,
build_scoped_file_url(@docs, relative_path) as scoped_file_url,
func.chunk as chunk,
snowflake.cortex.embed_text_768('e5-base-v2',chunk) as chunk_vec
from
directory(@docs),
TABLE(pdf_text_chunker(build_scoped_file_url(@docs, relative_path))) as func;Prompt Engineering and LLM Orchestration: with Streamlit, you can use a framework like LangChain to manage prompts and use Snowflox Cortex LLM Functions to interface with supported LLMs such as below:
prompt = f"""
'You are an advisor assistant extracting information from the context provided.
Answer the question based on the context. Be concise and do not hallucinate.
Ignore the case sensitivity. You must be elaborative in your response with bullet points.
Context: {prompt_context}
Question:
{question}
Answer: '
"""
cmd = f"""
select snowflake.cortex.complete(?,?) as response
"""
response = session.sql(cmd, params=[model_name, prompt]).collect()
res_text = response[0].RESPONSEThe entire technology stack can be visualized as below:

Search and Chat AI Assistant Application Demo
Working code and a running application builds more confidence than the theory and here is a prototype version to demonstrate the concept:
To conclude, Snowflake’s Cortex, Snowpark, and ML capabilities offer an easy and integrated managed-service interface for data analysts and data engineers. That makes it a compelling solution option particularly for existing Snowflake’s customers to build Generative AI apps closer to the data warehouse and data lake managed in the Snowflake ecosystem.
References:
Disclaimer:
All data and information provided on this blog are for informational purposes only. The author makes no representations as to the accuracy, completeness, correctness, suitability, or validity of any information on this blog and will not be liable for any errors, omissions, or delays in this information or any losses, injuries, or damages arising from its display or use. This is a personal view and the opinions expressed here represent my own and not those of my employer or any other organization.